在上一篇 《AI 原生游戏开发实践 · 从资产复用到经验复用》 里,我提出过一个观点:玩法验证期不必等待正式美术,可以复用既有资产 + AI 重组,先让玩法运转起来加以验证。那篇文章留下了一个引子——”后续结合实际案例,把这条流程从头到尾完整执行一遍”。
本文即是该案例的展开。
本文选取的样本,是把某第三人称射击游戏的角色与怪物资产——网格、骨骼、动画、材质——从游戏封包中逆向解包出来,经过一条自建管线导入目标引擎,转化为可挂载骨架、可驱动、带材质的资产。整个过程遇到了十余处典型问题:从”导入后整体塌缩”,到”表面有五级 LOD、实则为假”,再到”材质赋上后通体花斑”。
这并非一篇”资产搬运教程”。它是一份真实的逆向 → 排查 → 定位 → 修复的复盘,每一处问题都有数据证据,而非泛泛提示”需注意某事项”。本文更希望阐明的是:当面对一个没有文档、只有二进制的黑盒时,凭借什么将其逐步拆解、厘清。
更进一步说,本文真正要验证的,并非”资产能否导入引擎”——那只是表象。它要验证的是:AI 能否帮助我们把一个黑盒资产管线,转化为可理解、可维护、可复用的工程流程。 把他人封装、加密、且无任何文档的对象,在 AI 的协助下拆解、读懂、补全工具能力、最终沉淀为一条自己可掌控的管线——这正是本文归入”AI 原生开发实践”系列的理由。资产逆向只是载体,AI 辅助分析一个黑盒系统才是主题。
定位与合规声明 · 本文是引擎美术管线的学习与原型验证记录,目的在于打通”从二进制资产到可用引擎资产”这条技术链路,用于研究与原型阶段。解包用的是社区在 GitHub 上开源的解包工具,本文的工作是在其源码基础上做定制扩展(补多套 UV、修缩放、修朝向、分级 LOD、dump shader 等),并不涉及自行破解游戏的加密或保护机制。文中一律以”某第三人称射击游戏””目标引擎”等代称,不点名任何具体作品,不公开封包路径,也不鼓励将他人资产用于实际产品。这与上一篇的立意一致:外来资产只承担开发期的验证占位,验证通过后由自制资产替换。
一、先看清这条管线长什么样
在深入每一处问题之前,先把整条管线呈现出来,后续所有问题都发生在这张图的某一环节上。

一句话概括,按实际执行的先后:
“`
游戏封包 → 解包,解出网格 / 骨骼 / 动画 / 材质引用
→ 网格:导出 FBX(多套 UV / 正确朝向 / 正确缩放)→ 导入引擎 → 关联骨架与动画
→ LOD:逐级导出、逐级挂载,辨别真假分级
→ 材质:dump 真实 GPU shader,逆向出合成算法 → 引擎主材质 + 实例 → 赋到网格
→ 验证:逐级数据对比 → 覆盖正式工程 → 版本控制提交
“`
把顺序排成”网格 → LOD → 材质”,并非随意为之——它正是资产在引擎中成型的物理顺序:先将模型与动画导入并摆正,再将多级 LOD 分级挂载,最后才在这个已摆正、已分级的网格上赋予材质。每一环节都潜藏着只有亲手实践才会遇到的问题。下面便按此顺序逐环拆解。
二、解包:先搞清楚能拿到什么、拿不到什么
逆向的第一步,是打开游戏封包,查看其中包含什么。
这一步所用的工具,是社区在 GitHub 上开源的解包工具——封包格式早已被社区研究透彻,工具是现成的。我所做的并非从零破解,而是在其源码基础上做定制扩展:后文将提及的多套 UV 导出、缩放修正、朝向修正、分级 LOD、以及 dump GPU shader,都是向这个开源工具中新增的功能。
这里需要先明确一点:真正的工作量并不在解包。 解包是社区已经解决的、现成的一步;真正耗费精力的,是借助 AI 协助分析二进制结构、读懂 GPU shader、补全这个开源工具缺失的能力,把”能导出”提升为”能用于验证”。这条脉络与上一篇《从资产复用到经验复用》恰好衔接:上一篇主张复用既有资产以验证玩法,本文则回答”那些外来资产究竟如何才能变得可用”——答案是 AI 辅助下的一次次工具补全与数据核对,而非简单的搬运。
比”解出文件”更重要的认知是:你能获取的,与你以为能获取的,往往并非同一回事。
解包后可直接获取的:网格的顶点与拓扑、骨骼层级、蒙皮权重、动画曲线、以及材质对一组贴图的引用关系(哪个材质引用了哪几张图)。
无法获取、或者说”获取后也无法直接使用”的:
- 顶点的多套 UV,默认仅导出第一套。 而材质的不同贴图,恰恰对应不同的 UV 套。
- 多级 LOD 的结构,容易被工具误读——表面已分级,实则分级有误(后文专门讨论)。
- 不存在传统意义上的展开 albedo 贴图。 该游戏的机械单位材质为程序化合成——解出的”贴图”是一组掩码图、查找表、索引图,它们并非供人观看的颜色,而是供 shader 运算的数据。直接赋上,便是一片花斑(材质一节详述)。
因此,解包并非终点,只是在黑盒上撬开了一道缝隙。真正的硬仗在后续三环节:网格如何摆正、LOD 如何辨别真假、材质如何运算。
三、网格导入:连撞三道坎
把网格导入引擎,这一步看似最简单,却接连遇到三道难关,每一道都不是”查看代码”能发现的,而是”比对数据”才得以揭示的。

下面三道难关,先逐个排查阐明;上方这张”跑通后”的形态,是三道难关全部解决的结果。
第一道难关:导入后塌缩成团
现象: 部分单位导入后整体塌缩至原点附近,包围盒高度从一米变为一厘米;另一些单位却完全正常。同一套工具、同样的流程,结果迥异。
排查过程如同侦破:
- 先怀疑是导出工具损坏了数据。将正常版与异常版的 FBX 做逐字节比对——顶点坐标完全相同,排除。
- 再逐项比对骨骼数、蒙皮簇数——全部一致,动画数据未被改动。
- 最后比对 bind 矩阵的平移列:正常版的平移被乘以一百(换算为厘米),异常版未乘(仍为米)。
真因由此明确:导出时顶点坐标做了米→厘米的换算(乘一百),但骨骼的 bind 矩阵平移遗漏了同步换算。 于是网格处于厘米尺度、骨骼 bind 处于米尺度,二者错位一百倍——网格被一个缩小一百倍的骨架牵拉,随即塌缩。

修复: 在导出工具的源码中,令缩放因子同时作用于顶点与 bind 矩阵——要么皆乘,要么皆不乘,天然一致,不为”仅改其一”留下空间。
这道难关给出的并非”记得乘一百”,而是一种排查方法:
当两个版本结果不同、但代码看似一致时,应比对数据,而非比对代码。 包围盒高度是 140 还是 1.4、平移列是否乘以一百——数据上的差异即是铁证,代码里那行你以为”两侧均已执行”的缩放,数据会告诉你它实际只执行了一半。
第二道难关:朝向相反
现象: 导入后,角色背对镜头。
这道难关在朝向上我推测了五轮,全部有误:
- 怀疑导出工具改动了根节点旋转 → 比对 FBX 根节点,字节一致,排除。
- 怀疑缺少某个导入选项(轴向转换)→ 补全后,仍然相反。
- 怀疑是”合并导出”与”单体导出”的差异 → 文件相同,排除。
至第五次,才转换思路:不再纠结”为何相反”,而直接以包围盒数据对齐。正常版的包围盒原点 X 为 +22,异常版为 −22——恰好是绕竖直轴旋转了一百八十度。
修复: 导入时增加一个 yaw = 180 的旋转予以抵消,使包围盒数据与正常版对齐。仅旋转整体、不触及顶点与蒙皮,动画安全。
在朝向上推测五轮全部有误,最终凭包围盒数据对齐一举解决。有时无需弄清根因,数据吻合即可。 “理解原因”固然重要,但当它迟迟无法给出答案时,”用数据对齐”往往更快抵达终点。
第三道难关:UV 不匹配,材质模糊成片
现象: 这道难关要到赋材质时才会暴露——材质赋上后,呈均匀的一片肉色,完全缺失应有的细节纹理。但根因位于网格导入阶段,故置于此处阐述。
材质算法正确、贴图也正确,那么问题只可能出在 UV。最初我以为身体材质应使用那套”看起来最规整”的 UV(范围在 0 到 1 之间),结果便是模糊。
对照游戏 shader 方才明了:主图(索引图、法线图)使用的是平铺 UV——范围在 0 到 8,将一张低分辨率的图重复铺八次以堆叠细节;那套规整的 0–1 UV,是供细节叠加层使用的,而非供主图。
“采样最平滑的那套 UV”并不等于正确。 低分辨率的索引图,依靠平铺重复来堆叠细节,平铺 UV 才是它应使用的。直觉会促使你选择那套”看似干净”的 UV,但材质算法究竟使用哪一套,需到 shader 中查证。
修复: 为导出工具增加多套 UV 的支持(导出所有 UV 套),在材质中指定使用正确的那套。这也正是解包一节所言”默认仅导出第一套 UV”构成隐患的原因——它要到材质阶段才发作。
三道难关解决之后,网格不仅是”已导入”,而是骨骼层级完整、蒙皮正确、动画成套可播放:
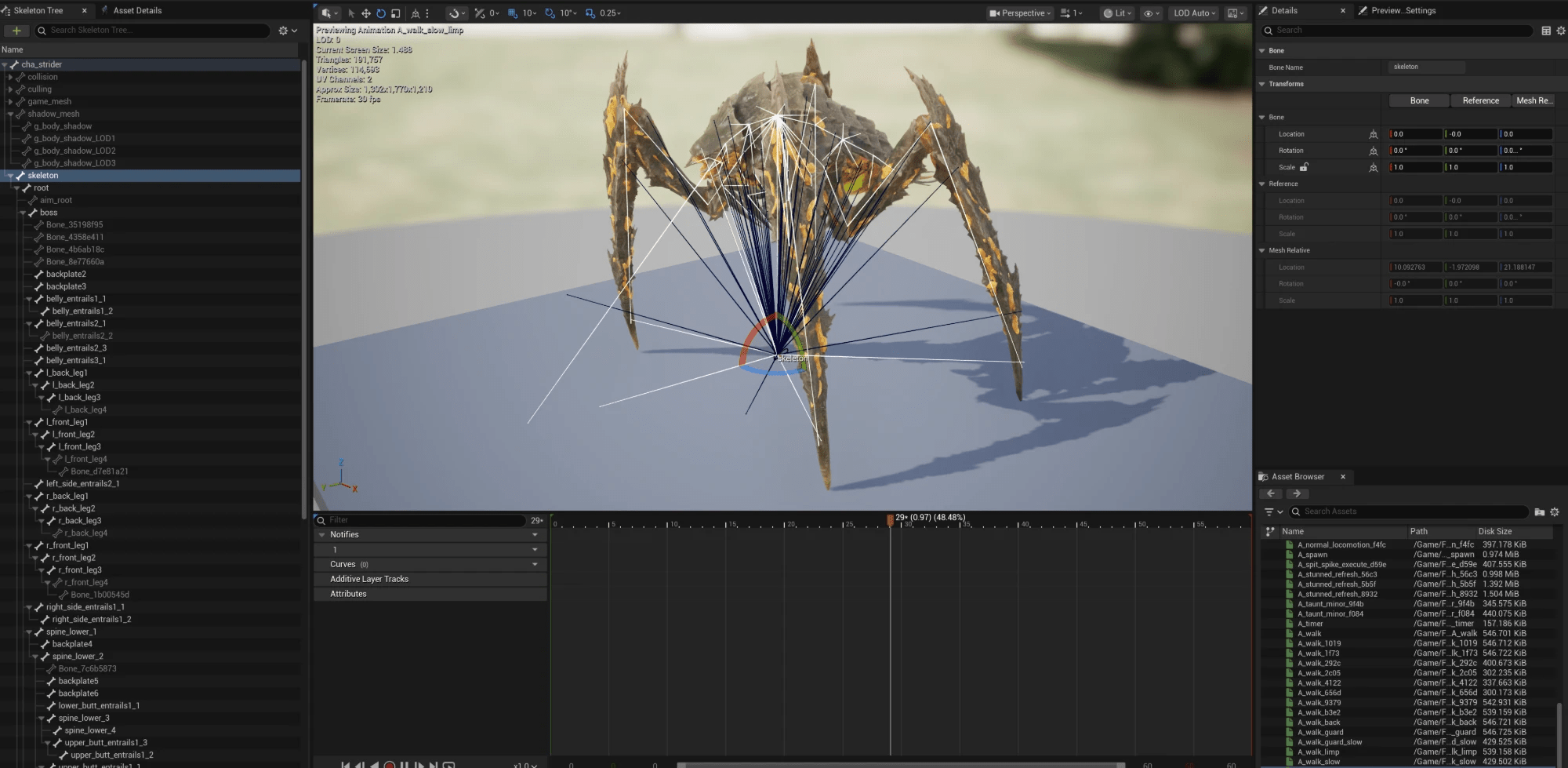
四、LOD 的陷阱:看着有五级,其实是假的
网格摆正之后,下一步是处理多级 LOD。这是全篇最具代表性的一节,也是将”数据驱动”阐释得最为透彻的一节。
现象: 批量导入后,部分单位 LOD 切换时面数几乎不降——从最高模切换到最低模,仅下降百分之二十,而正常的 LOD 应当下降百分之九十以上。
问题在于,“它有几级 LOD”这一数字是正确的——五级,一级不缺。若仅观察这一表面指标,根本无法发现问题。
如何发现:逐级读取真实顶点数
定位问题的方法,不是查看”有几级”,而是逐级读取每一级 LOD 的真实顶点数,并列成一行:

正常单位:
“`
44270 → 15370 → 4548 → 1520 每级减半,是真 LOD
“`
异常单位:
“`
111329 → 96698 → 89883 → 88166 只降 20%,是假 LOD
“`
两行数字并列呈现,真假立判。正常的那条是陡降的阶梯,异常的那条几近平直。
真因: 这些异常单位的最高模网格,被按 UDIM 切分为多个材质块(每块顶点数相近)。导入工具将这些 UDIM 块误判为多级 LOD,而真正的简化 LOD 反被忽略。表面上凑足了”五级”,实则是五块大小相近的材质分块。
修复:每级 LOD 单独导出为一个文件
修复方案并未在导入工具中构建复杂的 LOD 识别逻辑(那会使 UDIM 分块与 LOD 检测的耦合愈发紧密),而是采用了一种更直接的思路:
将每一级 LOD 单独导出为一个 FBX 文件,再借助引擎的 LOD 导入接口逐级精确挂载——彻底规避 UDIM 分块与 LOD 检测之间的纠缠。L0 一个文件、L1 一个文件、L2 一个文件,各自导出,引擎逐级挂载,不给它”自行推测哪一级是 LOD”的余地。

修复之后,同一个单位的逐级顶点数:
“`
87417 → 17334 → 6753 → 1840 → 439 减面 99.5%
“`
这才是真 LOD 应有的形态。

全篇最重要的一条方法论:逐级数据对比,胜过观察表面指标。 “有五级 LOD”这一指标是正确的,但逐级顶点数一经比对便暴露破绽。定位问题的,从来不是更精巧的分析,而是更细致的数据。
五、材质逆向:不是猜出来的,是读 shader 读出来的
网格摆正、LOD 分级正确之后,最后一步是为其赋予材质。这是整篇最具技术深度的一节。
机械单位的材质没有现成的彩色贴图,那么它的颜色究竟从何而来?最初我的做法是——查看解包工具给出的贴图映射,凭”这张看似 albedo、那张看似法线”,套用一个现成的标准主材质。
这个思路,出现了三次失误。
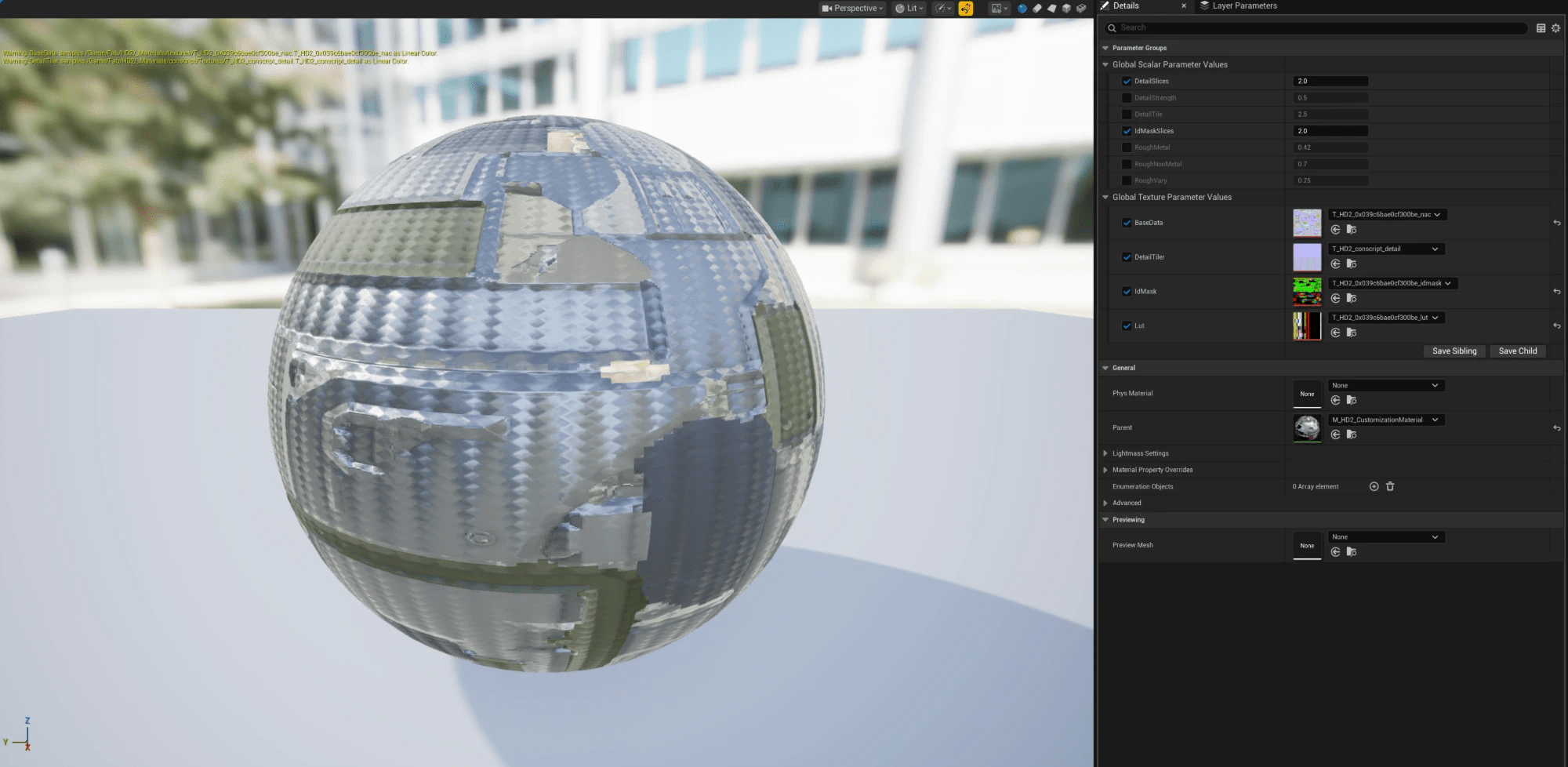
- 第一次,将索引图当作 albedo 赋上——结果是一片均匀的色块,因为索引图本身并非颜色,而是一组用于查询调色板的索引值。
- 第二次,将损伤图当作法线赋上——结果金属的高光被放大为花斑。
- 第三次,将一个alpha 裁剪材质当作”整片自发光”处理——整个部件都在发光。
三次都失败于同一个动作:凭外观与文件名推测贴图的用途。
关键转折:为何必须去读 shader
三次推测失误之后,真正的转折不是”换一种更准确的推测”,而是彻底放弃推测——去读取游戏运行时真正执行的那段 GPU shader。借助 AI 将其反编译为可读代码,游戏究竟如何计算出这个颜色,便逐行呈现于眼前。
这一步是整篇的方法论核心,值得充分阐明:材质的真相不在贴图的外观中,而在计算它的那段代码里。 贴图的外观会误导你——索引图看似噪点、损伤图看似法线;但 shader 不会误导你,它明确写明每张图被当作何用、如何参与运算。不要推测,要看证据,这里的证据正是 shader 本身。前述三次花斑,本质都是”以外观当证据”的代价。
读取 shader 自然有可取巧之处:一个材质会产出诸多变体,选取那个最纯净的渲染阶段去读取——无光照、无后处理、只输出材质本身的那个,数百行即可将算法读完;混入光照与调色的那些反而更长、更难读。但这些只是技巧,核心仍是那句:算法是读出来的,不是推测出来的。
读通之后,机械单位材质的算法骨架如下:
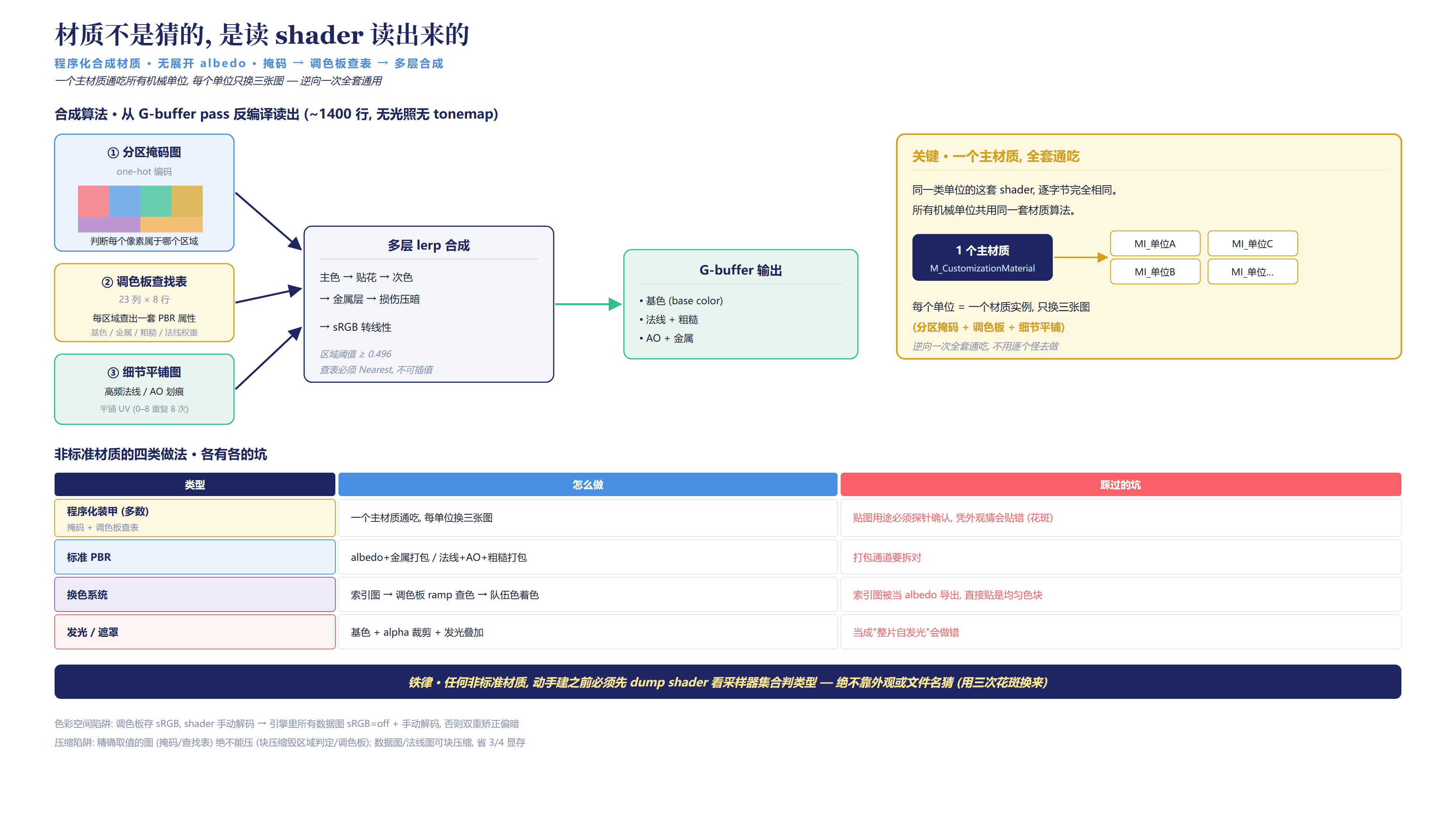
“`
掩码图(one-hot 编码,判断当前像素属于哪个区域)
→ 调色板查找表(每个区域查出一套 PBR 属性:基色 / 金属 / 粗糙 / 法线权重…)
→ 多层 lerp 合成(主色 → 贴花 → 次色 → 金属层 → 损伤压暗)
→ sRGB 转线性
“`
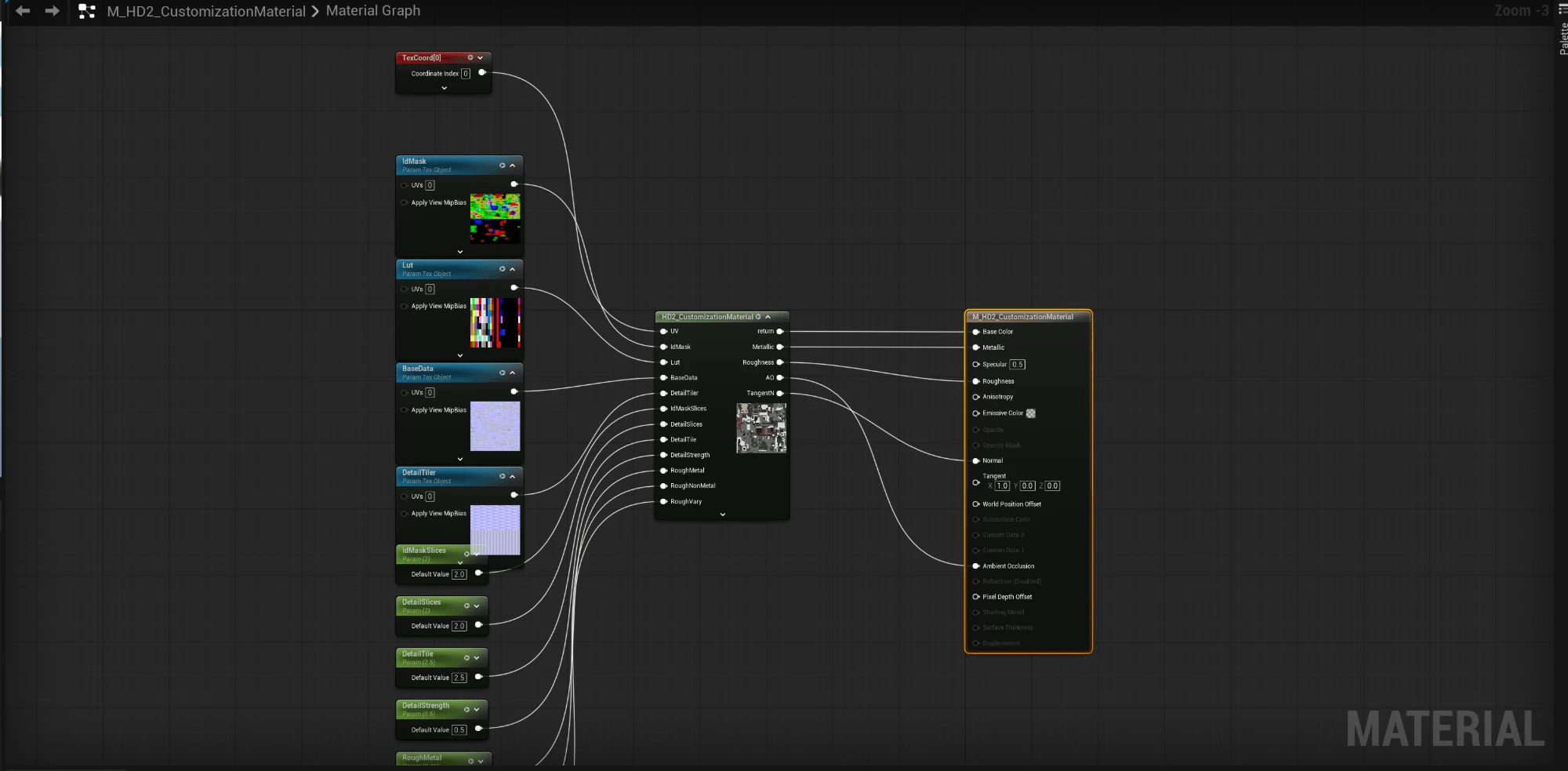
最精妙的一点:同一类单位(无论是步兵还是其他机械)的这套 shader,逐字节完全相同。所有机械单位共用同一套材质算法,每个单位仅替换三张图(分区掩码 + 调色板 + 细节平铺)。
落实到引擎中,这意味着:只需制作一个主材质,每个单位对应一个材质实例,将那三张图设为纹理参数。逆向一次,全套适用,无需逐个怪物分别处理。
非标准材质的四类做法
并非所有材质都采用这套程序化合成。将几类材质与各自的问题并列,对照查阅:
| 材质类型 | 处理方式 | 遇到的问题 |
|—|—|—|
| 程序化装甲(占多数) | 掩码 + 调色板查表,一个主材质适用全部,每单位替换三张图 | 贴图用途须以探针确认,凭外观推测会赋错(花斑) |
| 标准 PBR | albedo + 金属打包、法线 + AO + 粗糙打包 | 打包通道须正确拆分 |
| 换色系统 | 索引图 → 调色板 ramp 查色 → 队伍色二次着色 | 索引图被当作 albedo 导出,直接赋上为均匀色块 |
| 发光 / 遮罩 | 基色 + alpha 裁剪 + 发光叠加 | 当作”整片自发光”会处理有误 |
四类之中,程序化装甲与换色系统存在一个共同的陷阱:它们解出的”贴图”皆非颜色,而是用于查表或充当索引的数据图。 这正是凭外观推测必然出错的原因。
一条以代价换来的铁律
任何非标准材质,在动手构建之前,必须先 dump 它的 shader,查看采样器集合以判断类型——绝不凭外观或文件名推测。
采样器的名称(例如”索引发光””调色板颜色””次表面透明度”)会直接表明这是哪一类材质、每张图各司何职。审视一遍采样器集合,远比盯着缩略图反复推测可靠。这条铁律,是以三次花斑为代价换来的。
两个经典陷阱:色彩空间与压缩
读懂算法之后,还有两个工程细节容易令人受挫:
色彩空间的双重矫正。 调色板中存储的是 sRGB 颜色,而 shader 内部会手动执行一次 sRGB→线性的转换。因此在引擎中,所有这些数据图都必须设为 sRGB = off,再于材质中手动解码,方能等价于游戏。若将图设为 sRGB = on,引擎会再矫正一次,结果便是整体偏暗——这是一个经典陷阱。判断一张图是否应开启 sRGB,不能只看 shader 中是否有解码,还须查证其纹理格式(线性格式即为线性,不应再叠加一层)。
贴图压缩须按用途区分。 需精确取值的图(掩码、查找表)绝对不可压缩——任何块压缩都会破坏区域判定或调色板查色,掩码图一经压缩,区域边界即紊乱,调色板一经压缩,颜色即损毁。而数据图、法线图可采用块压缩,误差可接受,能节省四分之三的显存。早期为图省事一律设为无压缩,结果仅一类法线数据图便占用一千多兆显存;按用途分类之后,降至不到三百兆。
六、批量化与收尾:从一个到几百个
单个单位跑通之后,接下来是工程化——将这条管线推广至九十个怪物加三百五十六个角色,每个都需完整执行”分级导出 FBX → 导入 → 关联骨架 → 逐级挂载 LOD → 赋材质”。这一段并无技巧炫示,全是将流程做扎实的细节:
- 断点续跑。 导出一批需运行数小时,脚本必须支持中断、支持续跑——已导出的予以跳过,不必每次从头重来。
- 覆盖前必做对比。 在以新资产覆盖旧工程之前,先生成一张新旧对比表,确认材质与 LOD 未出现退步;物理备份一份;再行覆盖。这一步呼应上一篇的”双线并行”——唯有经过验证的内容方可放入正式工程。
- 跨工程同步。 测试工程与正式工程使用的是两个不同构建的引擎,引擎构建标识各异。资产可直接拷贝过去,但拷贝之后必须重新验证一遍——不应假设两个引擎下表现一致。
- 版本控制拆批提交。 单次提交超过两千个文件会触发连接超时,故按大约一千个一批拆分提交;工具源码的改动单独成一个提交,与资产分离,提交历史方能清晰。
七、复盘:这趟逆向真正学到的
将整篇归纳为几条,并非技术清单,而是面对黑盒时的思维方式:
第一,材质不是推测出来的,是将游戏的 GPU shader 反编译后读取出来的。 看到贴图映射便套用现成主材质,出现了三次失误。任何非标准材质,先 dump shader、看采样器以判断类型,绝不凭外观推测。
第二,两个版本结果不同、代码却一致时,应比对数据,而非比对代码。 塌缩问题正是如此定位的——顶点与骨骼 bind 的缩放仅对应了一半,代码中无从察觉,矩阵数值中一目了然。
第三,有时无需弄清根因,数据吻合即可。 朝向那道难关我推测五轮根因全部有误,最终凭包围盒数据对齐一举解决。理解原因固然重要,但当它无法给出答案时,不应在此空耗时间。
第四,逐级数据对比,胜过观察表面指标。 “有五级 LOD”是正确的,但逐级顶点数一经比对便暴露破绽。这一条贯穿全篇——塌缩比对的是包围盒与矩阵,朝向比对的是包围盒原点,LOD 比对的是逐级顶点数。真正帮助你穿透黑盒的,不是更精巧的推测,而是更细致的数据。
回到开头那个观点。上一篇主张,玩法验证可以复用既有资产、先运转起来。本文则是它在工程实践层面的展开——真要将外部资产搬入引擎用于原型验证,中间这条管线远非”导入一下”那般轻松,它是一连串”看似正确、实则有误”的问题。能将它们逐一解决,凭借的不是运气,也不是更强的工具(工具是 GitHub 上现成的),而是每遇阻碍,即回退至数据层面比对。
八、AI 协作复盘:这篇是怎么和 AI 一起做完的
关于这个栏目 · 自本篇起,”AI 协作复盘”将成为本系列每一篇的固定收尾。它固定回答四个问题:AI 提供了什么、AI 在何处失效、人如何补位、最终如何解决。 一个论述”AI 原生开发”的系列,若只展示打磨干净的成果、而不记录协作中的真实摩擦,那才是最不”AI 原生”的。这一栏,正是本系列区别于普通技术博客之处。
这是一个”AI 原生开发实践”系列,因此须诚实以对——上述那条管线的逆向、调试、批量化,大量工作是我与 AI 协作完成的;而本文本身(正文、配图、发布),也是一次人机协作。以下是此次 AI 遇到的几处问题,以及人如何补位。
问题一:AI 试图自行截取引擎中的画面,却无法打开应用。 文中那几张引擎截图,原计划让 AI 通过桌面自动化自行截取。结果受阻于第一步——授权层反复报告”找不到该应用”,更换进程名、窗口标题及各种变体均不予识别。根因是此类自动化仅识别系统已注册的应用,而这套引擎的可执行程序不在其列。解决方式:由人直接接手截图。 教训很朴素——当一条自动化路径在你的环境中确实无法走通时,不应与工具反复较劲,换人完成那一步往往只需数秒。 AI 尝试七八轮才确认此路不通,人三十秒便完成了截图。
问题二:AI 能看到图,却无法保存图。 截图由人贴入对话,AI 能”看见”内容、能据此撰写图注,但没有任何工具能将对话中的图片落为磁盘文件——而要嵌入正文、上传发布,必须有磁盘文件。这一边界往复确认了数轮才得以厘清。解决方式:由人手动将图保存至指定目录,AI 再从磁盘读取处理。 这暴露了一个常被忽略的协作边界:AI 的”看见”与”获取”是两回事。 看见用于理解,获取方能加工,中间这道关须由人跨越。
问题三:AI 以为需要重做,实则任务已经完成。 英文翻译被指派给一个子任务执行,中途被打断。AI 的第一反应是”被打断 = 未完成,须重做”,正准备重新翻译,一经查证磁盘——子任务在被打断前其实已将整篇英文版撰写完毕并存盘。解决方式:先查证状态,再决定动作。 教训是:“流程被中断”不等于”成果不存在”——动手重做之前,先确认当前状态,不应以直觉代替检查。 这恰是全文那条方法论的翻版:不凭印象,而看数据(此处即查看磁盘上的实际产物)。
问题四:中文文件名与批处理脚本发生了经典的冲突。 上传配图的脚本第一版采用了一种数据结构来存储”中文文件名 → 上传名”的映射,运行时报告”路径含非法字符”,在中文文件名上失效。解决方式:改用不依赖该结构的写法,转为显式的成对数组。 这是工程上的老问题(非 ASCII 路径 + 某些 API 的组合),但它提醒人:AI 编写的脚本在”happy path”上往往无误,真正的问题在边界输入上——中文名、特殊字符、空目录,这些是须专门关注之处。
问题五:图已发布,一部分却未进入正文。 配图分两类(示意图与引擎截图),发布后查证发现,只有示意图进入了正文,引擎截图那一类未渲染出来。蹊跷的是:解析逻辑在交互式环境中逐行复现时,十一张图全部正确生成;可一旦作为脚本文件整体执行,便只剩五张。盯着代码反复审视,看不出任何差别——因为差别根本不在代码逻辑中。最终凭借比对实际产物(读取发布后的真实内容,清点其中究竟有几张图、有无图注)锁定:问题出在脚本文件的编码——发布脚本未存为带 BOM 的格式,而这台机器的 PowerShell 默认按本地编码读取脚本文件,于是脚本中一行中文注释的字节被误读,将紧随其后的一段处理逻辑”吞没”。为脚本补上正确的编码标记,十一张图立即全部就位。这一条与文中那个塌缩问题是同一教训的两次上演:结果与预期不符、代码却看不出问题时,应比对产物、查证环境,而非只比对代码。 此次”产物”是发布后的图片数,”环境”是脚本文件的编码——都不在代码本身之中。
将这五处问题归纳为一句话:AI 承担了大量重复、繁琐、可机械化的工作(逆向、批量、翻译、绘图、编写脚本),但每一个”环境边界”与”状态判断”的关口,都需要人精准地介入补位。 协作的效率不在于 AI 全程包办,而在于人知道应在哪一步接手——能截图的接手截图,能存盘的接手存盘,该查证状态时提醒查证。这本身,也是”AI 原生开发”须修炼的技艺。
这是实战篇的第二站。下一站,我将沿着全景篇那张地图,继续走向战斗、敌人、AI Director。
最后重申本文立意:这条管线是为学习引擎美术流程、验证原型可行性而打通的,工具源自社区开源、工作在于源码定制,不涉及破解游戏保护机制。外部资产在此仅为验证期的临时占位,一旦进入产品阶段,即应由自制资产替换——它本就不是终点,通往终点的那条路径,才是本文意图留存的内容。