This isn’t an article about what AI *can do*.
There are already too many of those lists — AI can write code, generate textures, run simulations. But piling those capabilities together does not automatically produce a development method that actually ships. The real question is: when you want players to feel a certain way, how does AI help you turn “the experience you want” into “a playable, validated prototype”?
In my previous post, *AI-Native Game Development — From Pipeline Refactoring to Dynamic Experience*, I made an argument: what AI Native really changes isn’t AI-generated assets — it’s that the game industry, for the first time, is shifting from “a competition over asset-production capacity” to “a competition over experience-validation speed.” The most competitive team isn’t the one with the most art assets; it’s the one that can fastest validate *what’s fun*.
That post was about why. This one is about how.
If validation speed is the new battleground, the very next question is: when you want players to feel a certain way, how exactly does AI help you turn “the experience you want” into “a playable, validated prototype”? The previous post discussed combat, enemies, and levels as separate pipelines; this one pulls them into one unified framework — so that “from experience to validation” walks the same path in every system.
So this post is a map. For each system I’ll lay out how it starts from an experience goal, how AI assists in delivery, and how it gets validated — including why it’s done this way, and where the boundaries are. Later I’ll expand each system with concrete examples; this post first stands up the whole framework.

One thread running through everything
Whether it’s combat, enemies, or levels, the method is actually the same line:
Experience Goal → Function + Values (config-driven) → AI-Assisted Delivery → Validate & Iterate
These four steps look plain, but the order and the division of labor in each one matter.
Step one, the experience goal. First get clear on what you want players to feel — game feel, emotion, pacing, progression. This is the starting point, and it’s the judgment AI cannot make for you. Many teams skip this step and jump straight to building features, only to discover halfway through that it’s “not fun” — and they can’t articulate exactly what’s not fun, because they never defined what “fun” was supposed to be. An experience goal isn’t an empty phrase; it has to be translatable into something verifiable, or the next three steps have no target.
Step two, function + values. Code defines the skeleton; values define the expression. The key discipline here: iterate by tuning values, not by repeatedly changing code. Every code change carries the risk of introducing bugs, needs retesting, needs re-review; a value change is a hot reload that doesn’t touch logic, with near-zero risk. So the best reliability, it turns out, is to write less code and change less code — expose everything that might change as config at the moment you write the code.
Step three, AI-assisted delivery. AI finds references, translates, generates in bulk. Note the division of labor — humans decide, AI executes. AI doesn’t judge “whether this value is good”; it turns your judgment into reality, fast.
Step four, validate & iterate. Machine runs + human tests, compared against the experience goal. Below target — go back and fix. This forms a closed loop.
The single most important line on this thread: validate that it’s fun first, then invest in assets. The biggest waste in traditional development is the art taking three weeks before anyone realizes the gameplay direction was wrong — by which point the cost of tearing it down is enormous, so you’re forced to “bet on the direction.” But when gameplay can be validated quickly with placeholder assets + values, you discover the wrong direction the moment it appears, change a parameter, and no one gets hurt — the cost of rejecting a bad direction is near zero. That’s the fundamental change AI brings to gameplay development: not making you build faster, but letting you reject mistakes earlier.
The three systems below are concrete expansions of this thread. The only difference: each system anchors to a different “experience.”
Combat System: the anchor is the combat experience
The combat system’s experience anchor is the combat experience — and game feel is the *means* to achieve it. Game feel on its own is too vague; in practice it splits into two layers — function (mechanics like hit detection, damage, abilities, Buffs) and values (parameters like TTK, crit, recoil, cooldown) — plus 3C (Character, Camera, Control). Each layer is a function-plus-values pairing: function holds up the skeleton, values determine the feel — and game feel ultimately serves that combat experience that keeps players wanting one more fight.
There’s a counterintuitive but critically important order here: function comes before values.
A concrete example. The same “ADS sensitivity 1.2” means completely different things under different functional implementations: does the camera FOV transition linearly or with easing? Does sensitivity scale proportionally with FOV (is there an ADS multiplier)? Can you fire mid-aim-transition, and what happens if it’s interrupted? These are all function-layer design. If the function isn’t settled, the “1.2” you’re tuning has no anchor — it’s stable under one implementation and drifts under another. So the correct order is: get the function clear, implement it, expose the parameter interfaces well, and *then* values mean something.

I sum up AI’s role in the combat system in one line: AI finds references, humans decide.
Here’s how it runs. The designer describes intent in genre language — say, “match the shooting feel of CoD, but with more agile movement.” Note: the designer states intent, not specific numbers. Then AI does two things: first it understands the functional mechanics (translating “what CoD’s ADS does” into “what we need to implement” — FOV transition curve, multiplier, can-you-fire-mid-switch), then it assists implementation (generating runnable code skeletons, exposing all tunable parameters, writing hot reload and unit tests). Once function lands, AI then extracts values: pulling parameters from the reference, applying a differential bias for the “more agile movement” requirement (movement +15%, turn damping −20%), each item carrying a traceable source.
Then comes the step I consider the most critical and the most often overlooked — humans and AI co-create the test cases.
Traditional “review” is one-directional: a human finds faults in AI’s output and gives feedback. But co-creating test cases is bidirectional: the human states experience intent (“in a close-range encounter, the player should be able to decide fight-or-flee within 0.5 seconds”), and AI translates that vague intent into an executable test scenario (“player at 5m, 8 rounds in the mag, enemy head-on — check whether TTK ≤ 0.5s”). The real value of this step is forcing the human to make the intuition of “I think it’s fun” explicit, into a concrete standard of “under what scenario it should behave how.” These cases become the team’s shared consensus — when the machine runs and humans test later, everyone works against the same set of cases, with no “I say it’s fun, you say it isn’t” bickering. And cases are reusable and accumulate over time — this is the first time a small team has a shot at building an AAA-grade testing baseline.

Finally, dual-track validation.
One track is machine runs: virtual players run thousands of automated combats under the case conditions, tallying each case’s actual TTK, hit rate, win rate — validating “are the values right.” Its strengths are speed (seconds), objectivity, and volume, but it can’t test feel. The other track is human playtest: real players play with a controller, checking off the case library one item at a time, validating “does it feel good.” It catches problems like “the values are right but it hits like mush, no feedback,” but it’s slow and low-sample.
The key is that these two tracks are a division of labor, not a substitution: the machine filters values, the human tunes feel. The human’s starting point is already a machine-filtered good version, so they only need to fine-tune the final 5%.
Compared to the traditional “guess a number from experience → blind-tune in-game → change → tune again” loop, the difference of this method isn’t “AI helps you build faster” — it’s that the starting point goes from a random spot to a market-validated baseline. The traditional way might loop 20 to 50 rounds to land on something “okay,” and with no objective reference, it easily falls into a “still not quite there” death spiral; the new way has a benchmark and a case library, is objectively debatable and regression-testable, and converges in one or two rounds. The cycle compresses from two-to-four weeks down to one-to-three days.
Enemy System: the anchor is the emotional value the combat experience brings
If the combat system anchors to “what combat experience the fight delivers,” the enemy system anchors to the emotional value that combat experience brings — what the player walks away with after a fight. Emotional value doesn’t come from nowhere; it grows on top of the combat experience: only with a good combat experience can the enemy create emotional peaks worth remembering inside it.
This is where the enemy system most easily goes wrong. Many teams pour effort into “how strong this enemy is, how complex its behavior tree is,” and forget a more fundamental question: does this design create a “highlight moment” for the player? The experience of a fight isn’t uniform; it’s a curve with peaks and valleys, and what players actually remember are the peaks — those “crisis → turn” moments.
I anchor it with three variables: TTK × OODA × emotional value.

- TTK (Time To Kill) is the duration container of an engagement; it determines how many OODA loops the player can run.
- OODA (Observe → Orient → Decide → Act) is the player’s cognitive loop during that time. Put simply: OODA is one complete cycle of the player going from “spotting a problem” to “solving it.”
- The emotional peak is born in the “crisis → turn” critical moment within the OODA loop.
To make it concrete: the player gets locked on by an enemy (crisis), dodges with a slide and headshots back (turn) — satisfying. Two rounds left in the mag against a full-health enemy (crisis), lands the shot anyway (turn) — satisfying. A teammate goes down (crisis), they wipe three by themselves (turn) — that’s a highlight. None of these are about “the enemy being hard” or “the enemy being weak”; they’re about whether the enemy created a critical point within the OODA loop.
And TTK determines whether these critical points get a chance to happen. TTK too short (say 0.1s) — the player can’t observe, decide, act in time, and just gets one-shot, left with only frustration; TTK too long (over 10s) — too many OODA loops run, breeding fatigue and boredom. A just-right TTK + one complete crisis-to-turn OODA = a highlight experience.
So every function and value in the enemy system has to come back to this question: does it, within the TTK, let the player complete an OODA loop and produce an emotional peak? This rewrites the whole evaluation standard. The behavior tree isn’t just “making the AI move” — it has to create threat signals that pull the player into observing; the attacks aren’t just “dealing damage” — they need a readable wind-up that leaves reaction time; the reaction delay needs whitespace so the player’s action has room. AI with rubber-band instant-reactions is the counterexample — because the player can’t OODA in time; AI that stands still taking hits is also a counterexample — because the player doesn’t need to OODA. Values like HP and damage are the same: HP determines this enemy’s TTK, damage determines the TTK before the player gets one-shot, and both must accommodate at least one or two OODA loops.
A single enemy’s OODA is micro. When multiple enemies combine, a macro OODA emerges — “who do I hit first,” a prioritization judgment. So the overall composition (waves, squads, AI director) should intervene at the valleys of the emotional curve: when the player is too comfortable, add pressure; when too punished, give a breather.
So how do you validate something as subjective as “emotion”?

I split validation into three steps that converge layer by layer — quantity first, quality later.
Step one, machine runs hard metrics. Virtual players run thousands of matches, tallying TTK, player reaction time, OODA-per-minute, death rate, enemy-kill distribution. These are objective data, each metric with an expected range (and those ranges are themselves extracted by AI from benchmark games, not guessed). Cases below target get flagged red and filtered out in bulk first. This step converges thousands of cases down to hundreds.
Step two, infer emotion from player behavior. This step is unique to enemy-system validation, and the cleverest. AI doesn’t “feel” emotion, but it can recognize the objective signatures of emotion happening. The principle: an emotional peak triggers specific player behavior, so you can infer emotion backward from behavior. Three concrete moves: you tell AI “a low-health comeback kill counts as a highlight,” AI translates that into a precise predicate (kill while HP < 20% and the enemy had previously attacked the player); AI writes a script that auto-scans millions of log lines, marking at which second each match triggered which signals; then it stitches these discrete signals into an emotion curve and compares against the design goal, circling the segments where “it should have peaked but didn’t.” This whole process needs no “emotion” from AI; what it does is rule definition + data scanning + comparison — all AI’s strong suits.
Step three, the LLM watches replays. The first two steps have a blind spot: they can only recognize signals you’ve predefined, and behavior is an indirect inference (“the player dodged” doesn’t equal “the player felt good”). The LLM watching replays is here to patch these two holes. Feed game footage and input logs to a multimodal model, and have it — like “a veteran player who’s watched tens of thousands of hours of game videos” — mark a timeline: 0:15-0:22 tense, 0:22-0:25 highlight (low-health comeback), 0:40 frustration (stuck). It works because in training it saw vast amounts of game footage and commentary, and recognizes “what a highlight moment looks like” — it doesn’t feel emotion, but it recognizes the visual signatures of emotion happening. To be honest: this step is still early, its accuracy is climbing fast but isn’t fully trustworthy yet, so it suits being an assistive filter, not a replacement for the human final call.
The point of these three steps working together: run only the data, and the values are right but it might still not be fun; rely only on humans, and the cost explodes. Only by dividing labor across three steps can you validate emotion both fast and accurately. And every “misaligned” point is a clear fix directive — go back to the corresponding function or value quadrant and fix it.
Level System: the anchor is pacing and exploration
The level system’s experience anchor is pacing and exploration. But unlike the previous two systems, this layer has a particularity: it’s the assembly layer.
What a level designer actually delivers is the coordinated placement of four things: POIs (points of interest), the path network, enemies, and resources. A boundary to draw here — enemy *design* belongs to the enemy system (how strong this enemy is, how its behavior tree is written), resource *values* belong to the economy system (how much a medkit heals), but “what to place at this spot on this map, how many to spawn, which supplies to put down” — that’s the level system’s job. The level system takes the enemies the enemy system provides, the resources the economy system defines, the terrain the scene system provides, and places them at specific positions according to the experience goal.

And the core difficulty of these four things: they must coordinate, point at the same experience goal, and not cancel each other out.
A few counterexamples make it clear. If enemies are placed densely (to create tension) but resources are handed out generously (to relax), the two cancel and the player feels no tension at all. If POIs want to guide the player east (encouraging exploration) but the path network only goes west, the design intent falls flat. If a rare resource is piled at a POI, but that POI is in a dead end the path network never passes, the player can’t reach it — placed for nothing. So the real craft of level design is translating “this segment should be tense” into a recipe: combat POIs clustered + path network narrowed to a single line + high enemy density + resources cut off — all four serving “tension” together. Each recipe is a packaged rule of “experience goal → placement of the four.”
AI’s positioning here must be stated clearly: AI doesn’t understand level design itself. I won’t dodge this. What AI does is inherit the expertise of professional designers — taking the scattered, tacit experience of “which recipe for which experience” and structurally precipitating it into a recipe library, called up during production and refilled after validation. The first use may be very empty (no experience), but the more it’s used and refilled, the more valuable the library becomes, eventually turning into a team asset. This is the same principle as the combat system’s “continuously evolving test-case library” — both precipitate human tacit experience into explicit team assets.
With the recipe in hand, how does it land? I’ll only mention one methodological point here; the concrete UE implementation is left for the level system’s hands-on post.

The core idea in one line: config-driven. All four recipes drop into config tables, and a procedural approach reads the tables to generate — the designer edits tables to set intent, the tooling reads tables to land it automatically, and re-editing the table regenerates, without touching code. This is exactly how that main-thread “config-driven” manifests in the level system: programmers expose capabilities as config so designers can iterate by editing tables, and nobody has to change code frequently.

To put it a bit more clearly: every design output (POI, path network, enemies, resources) has a corresponding landing mechanism, and what connects “design intent” to “engineering implementation” in the middle is the config table as the handoff interface. The designer, on the table’s side, expresses “what’s wanted”; engineering, on the other side, handles “how to generate it.” With the two decoupled, iteration is fast.
Finally, how do you validate a level once it’s built? Same thing — collect data back and check against the experience goal: player trajectory, dwell time, death-point telemetry, generate a heatmap, and compare against the recipe’s intent: was the tense segment actually tense (did the four not cancel out)? Did players go to the POIs they should? Did they take the right path? Whichever recipe proves effective in real runs gets reinforced into the library; whichever flops gets its parameters corrected — the recipe library gets more accurate the more it’s used.
Future Directions: what else fits the same framework
With combat, enemies, and levels covered, this framework can actually extend to more systems.

Progression, loot & economy, quests & narrative are game systems on par with combat/enemy/level, all able to reuse the same main thread: Experience Goal → Function & Values → AI collaboration → Validate & Iterate. Runtime AI Director and PCG × AI are two cross-cutting capabilities that span all systems — the former makes the game “come alive” for each player, the latter makes content “grow itself.” The Director’s architecture was discussed in detail in the previous post (wave orchestration, event injection, content mutation — that set), so I won’t repeat it; I’ll only restate that one boundary — the previous post put it as “the LLM handles ‘what to think,’ the behavior tree handles ‘how to do it’,” which in this framework means the LLM only does between-match orchestration, and never steps in to make per-tick decisions.
These are just touched on here; later posts will expand each one.
The Technical Foundation: making all of this genuinely reliable and accessible
Everything above is about “what to do.” But whether all of it can ship depends on two technical foundations.
The first foundation: how to make AI write code reliably.
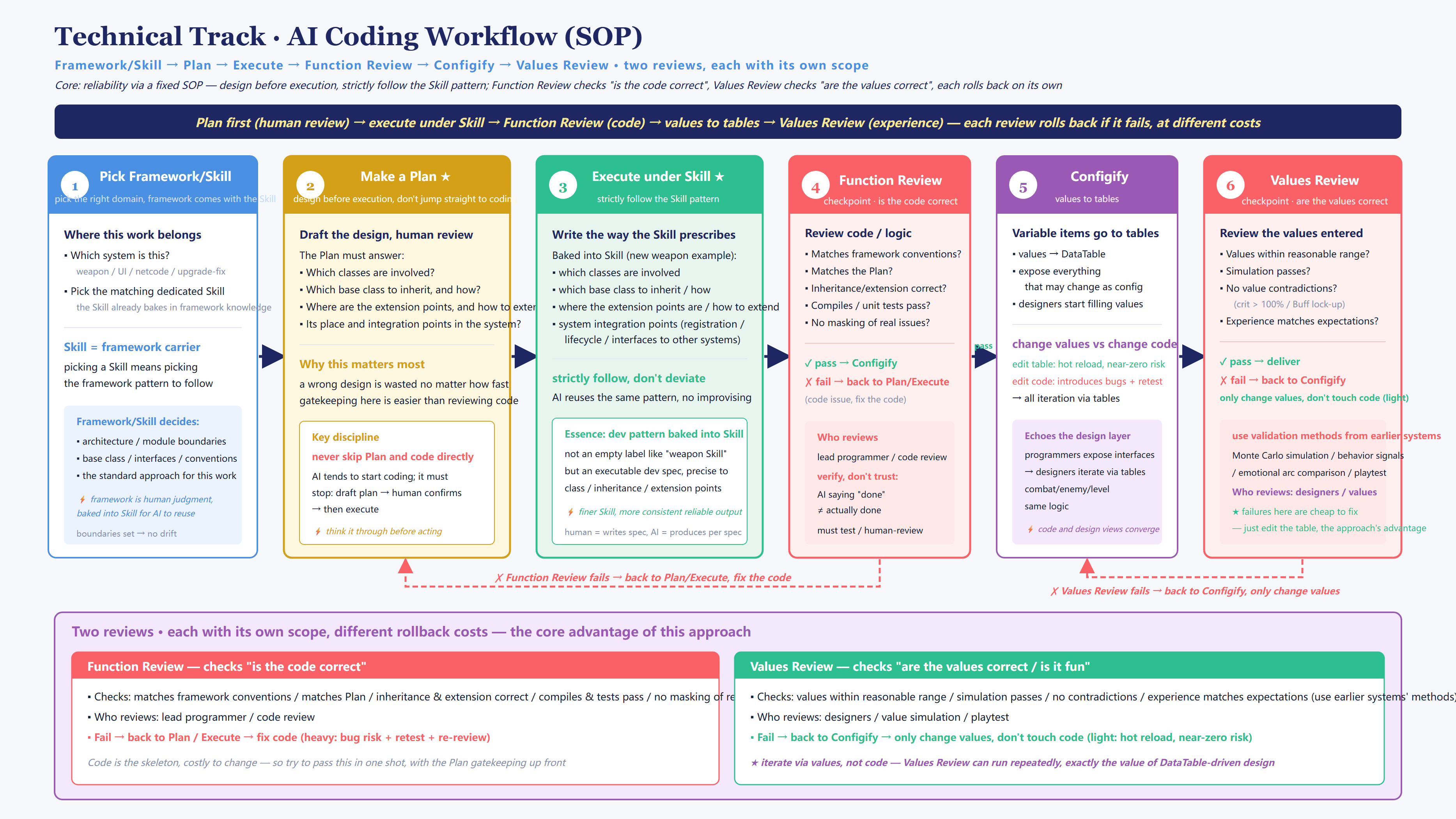
My answer — reliability doesn’t come from “AI being smarter,” it comes from a fixed development workflow (an SOP): Pick Framework/Skill → Make a Plan → Execute under the Skill → Function Review → Configify → Values Review.
I’ll only call out the most core judgments here; the full workflow gets its own dedicated post, *AI Coding SOP*. One, box the AI inside the existing client framework — it’s filling in blanks, not building from an empty lot. Two, produce a design Plan for human review first, and never allow skipping the Plan to code directly. Three, and the part most relevant to the gameplay systems — two reviews: the Function Review governs “is the code correct,” the Values Review governs “are the values correct.” Function Review fails — go back and change code, expensive; Values Review fails — only change the config table, don’t touch code, dirt cheap. This is exactly how the “iterate by tuning values, not changing code” that this whole post keeps stressing lands in engineering — code is the skeleton, get it right in one pass; values are the tuning layer, change and re-check repeatedly.
The second foundation: letting everyone use it, not just programmers.

The first foundation cuts programmers’ cost. This one cuts everyone’s cost — and it focuses on the gameplay-design and prototyping stage.
What AI plays here is a translation layer between people and the editor. In the traditional flow, for an artist or designer to land an idea, they first have to learn a pile of complex editor operations, menus, and parameter meanings, then do it by hand in the editor. With a translation layer, they express gameplay intent in plain language (“give me a shotgun with 0.4s close-range TTK,” “this segment tense, that one a breather”), and AI translates it into actual editor operations and configs, quickly landing a playable prototype.
It cuts three kinds of cost: learning cost (no editor operations, menus, parameter meanings to learn), usage cost (no manual clicking one by one — AI batch-executes), config cost (no field names to memorize, no fear of mistakes — AI generates and validates from intent).
And this layer connects directly to the prototyping of the four earlier systems. The designer says “match CoD feel, more agile movement,” and AI translates it into 3C parameter config, straight into the game to tune; the designer says “flanking melee enemies, spawn in groups of three,” and AI translates it into placeholder enemies + behavior config + spawn table; the designer says “this segment tense, that one a breather,” and AI translates it into POI/path/resource config generated by PCG. Each one is “designer states intent → AI translates → playable prototype, validate immediately.”
But the boundary must be drawn very clearly: this stage only builds the “gameplay prototype,” it doesn’t touch art presentation. The art at this stage is exactly the first of the four stages from the previous post — the validation stage: providing good-enough placeholders for gameplay (blockout characters, greybox, marketplace assets, temp VFX), serving the gameplay experience, not making polished final assets. The goal is “good-enough + fast,” because this stage is about validating gameplay. The later procurement, optimization, replacement, plus art presentation, rendering, lighting and materials, are not in this section — they’re left for later chapters.
The meaning of this layer is a shift in perspective: what AI cuts has never been “programmers’ cost” but everyone’s cost — freeing every role from “fighting tools” and putting their energy back on “judging whether the gameplay is fun.” And what AI cuts is only “operational cost,” not “judgment” — whether the gameplay is fun is always a human call. AI executes, humans decide.
In Closing
To collapse this map into one line:
AI doesn’t replace human judgment; it makes the path “from experience to playable prototype” 10× faster.
Humans set the experience goal and make the call; AI finds references, lands them, runs validation. The three gameplay systems each have their own experience anchor — combat anchors the combat experience, enemies anchor the emotional value that experience brings, levels anchor pacing and exploration — and the anchor determines “what to validate,” and validation drives iteration. Without an experience anchor, you don’t know what to validate, and AI has nothing to collaborate on. The anchor is the starting point of everything.
This post is a map. The articles that follow will be an ongoing record of a real development process.
Not a discussion of what AI can do.
But a discussion of — how, once AI truly enters game development, a team understands systems, validates experience, refactors gameplay, and ultimately turns ideas into a game.
The map is drawn. Next, we walk into each street.